Passage retrieval in context: Experiments on Patents
- DOI
- 10.24348/coria.2021.long_4
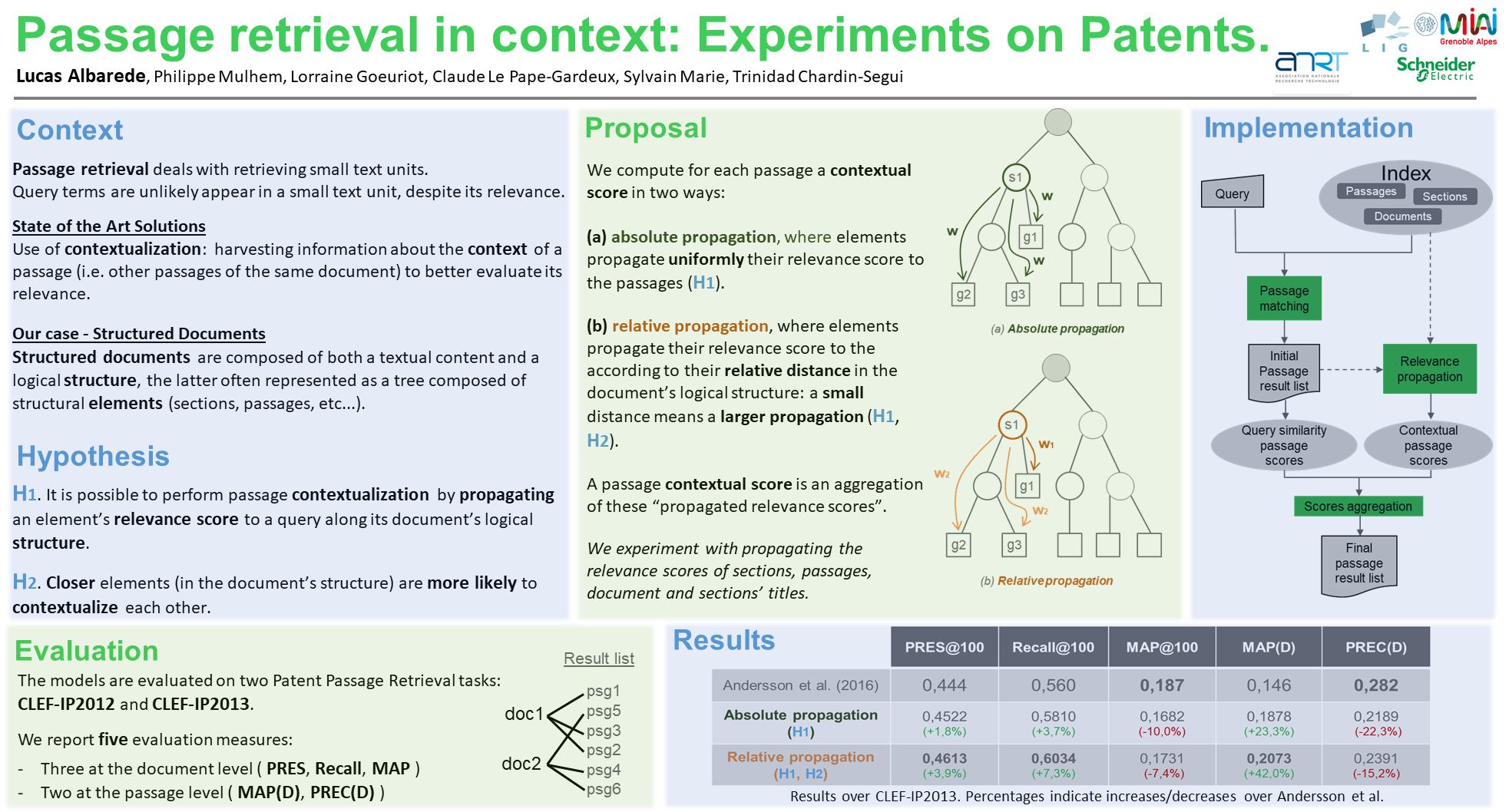
Focused retrieval retrieves and ranks sub-parts of documents according to their estimated relevance to a query. Many approaches akin to XML retrieval and Structured Document retrieval exploit documents structure to effectively retrieve logic elements (titles, sections, etc…). Other approaches like Passage Retrieval aim at retrieving arbitrary length text unit (passages), considering the document as a unstructured flat text. In this work, we use the best of the two worlds. We want to (1) retrieve passages to find the best text units to retrieve ; (2) exploit the document’s structure to more effectively estimate the passages' relevance. Previous work has shown that leveraging on the passage context was efficient for passage ranking. We believe that the information given by a document’s structure can be used to estimate its passages' context. Firstly, we propose several ways to represent and integrate a document’s structure and its sub-structures elements (sections) in the estimation of its passages' context. Secondly, we integrate these passage contexts in a state-of-the-art passage retrieval model. We evaluate our approach on two passage retrieval tasks on structured documents: CLEF IP2012 and CLEF IP2013. Our results show that using a document’s structure to estimate its passages' contexts improves retrieval performances.
![[ARIA]](/2021/sponsors/aria_hu3c83a9047e340d86eec2ca217f057ba3_15848_140x105_fit_box_2.png)
{kind=link}